
Немного об Apache NIFI
В эпоху импортозамещения и бурного развития Open-Source решений в области обработки данных и ETL & ELT процессов Apache NIFI прочно занял свое достойное место в наборе импортозамещенного технологического стека.
Этот инструмент в силу простоты освоения, низкого порога входа для разработчиков пайплайнов с данными и аналитиков зарекомендовал себя в качестве основного ETL инструмента для многих компаний. Однако сталкиваясь на практике с этой технологией, когда ставятся задачи обработки большого количества файлов и данных, достаточно хорошо ощущаешь потребность в понимании внутренней работы NIFI и острую необходимость оптимизаций пайплайнов.
Только столкнувшись со сложными кейсами обработки данных, фильтрациями, агрегациями, разбором каждой строки и приведением полуструктурированных или неструктурированных данных в структурированный вид становится отчетливо понятно, что Apache NIFI непростой инструмент для реализации ETL, который просто требует большого количества нервов у разработчиков.
Применение
В нашей практике есть неплохой опыт применения Apache NIFI как для различных предметных областей, так и для разных объемов данных. Удавалось применять NIFI для обработки мобильных данных (вот уж где настоящая Big Data), обработки событий пользователей с веб-сайта (событий было немного, но кейс интересный), и теперь подошла очередь более сложной задачи – обработки планов-графиков производства в excel-формате, трансформации и загрузки в базу.
Постановка задачи
Наша задача состояла в том, чтобы загрузить за короткий срок 15к файлов планов-графиков в формате Excel, которые накопились за 2 года, в базу данных PostgreSQL. Эти 15к файлов делились на 5 различных видов планов-графиков, и у каждого была определенная специфика, которую нужно было учесть.
Это привело к созданию 5 различных пайплайнов по разным планам-графикам. В целом пайплайны были одинаковы по количеству процессоров и их настройке, кроме процессора Get File, где у каждого пайплайна была своя входная директория и свой Replace Text, где мы заменяли название колонок файла для корректной вставки данных в нужные поля СУБД PostgreSQL.
После разработки, отладки, тестирования и запуска различных пайплайнов разработчику NIFI пришлось более 30 раз поднимать NIFI – из-за различных проблем с производительностью и памятью в NIFI. Но об этом немного позже.
Трудности
Трудности, c которыми наша команда столкнулась, - это внезапные ошибки с нехваткой Java Heap Space. Имхо, для многих могло быть ожидаемо, что такое большое количество файлов NIFI не прожуют в памяти и необходимо каким-то образом декомпозировать задачу. По факту NIFI не справлялся с большим количеством данных и постоянно падал.
Дополнительно в файлах присутствовали некорректные для обработки символы, которые приходилось заменять на другие.
Реализация
Изначально пайплайны состояли из 9 процессоров:
1) Get File
Этот процессор нужен для чтения файлов из указанной директории и их последующего удаления. Удаление файлов рекомендуется включать только после тестирования общего пайплайна. В нашем пайплайне мы настроили удаление файлов только после их успешной записи в БД.
2) Convert Excel to Csv
Чтобы работать с прочитанными файлами в Еxcel формате, нужно было конвертировать их в csv-формат. Если поток данных файлов постоянный, то рекомендуется в целях повышения производительности поставить интервал чтения файлов от 4 секунд и больше в зависимости от кейса, чтобы читать файлы одним пакетом и загружать в память NIFI для последующей обработки.
3) Split Text
Чтобы в дальнейшем загружать данные в СУБД, нам нужно поделить файл по строкам с сохранением первой строки (заголовок). Это позволит составлять необходимый SQL запрос в базу.
4) Convert Record
На выходе Split Text мы получаем файлы формата txt/csv, и, чтобы в дальнейшем не получить ошибки формата файла в процессоре Update Record, мы используем Convert Record для конвертации text/csv в точный csv-формат.
5) Update Attribute
Этот процессор был сделан для обогащения данных техническим полем даты со временем extract time для каждой строки, после чего оно сохраняется в переменную.
6) Replace Text
Первый Replace Text добавляет новую колонку extract time
7) Replace Text
Второй Replace Text непосредственно добавляет значение extract time
8) Update Record
Данный процессор использовался, чтобы исправить дату на нужный формат, исходя из требований к модели данных в СУБД.
9) Convert Record
Измененный, скорректированный и обогащённый csv-файл конвертирует в json-формат для последующей обработки.
10) Convert Json to SQL
Json-файл конвертирует в SQL – insert-запрос. Также надо не забыть таблицу в СУБД для загрузки, и ключи json файла должны соответствовать этой таблице.
11) Put SQL
Выполняет insert SQL-запроса вставки в СУБД.
Эксперименты
Сборка NIFI работала из docker-контейнера, а volume для данных, конечно, прокинуть забыли – и в результате локальные файлы на машине с планами-графиками в контейнере были не видны. Пришлось разворачивать заново NIFI, прокинув volume. После этого процессор Get File стал видеть все локальные файлы.
Далее в одном из пайплайнов обнаружили ошибку индексов в Convert Record из-за того, что value separator в Convert Excel to Csv была запятая, и в данных тоже была запятая, что, очевидно, приводило к неверному толкованию этой запятой в NIFI. В общем, можно было предвидеть, но вот никогда лишний раз не ожидаешь запятой в файлах. Но как показывает практика на разных проектах, то, что генерят пользователи вручную, может содержать абсолютно все, что угодно. И уж точно вставки в файлы любых символов, поэтому такую ситуацию в общем можно было предвидеть.
Мы решили данную проблему, заменив запятую на тильду “~” в Convert Excel to Csv. И создали 2 дополнительные сервиса чтения и записи csv с делиметром тильды.




Даже после замены запятой на тильду мы начали получать ошибку индексов в Convert Record, в некоторых файлах и на этот раз ошибка была из-за того, что в одной ячейке было 2 строки.
Решили проблему, добавив еще один Replace Text и через регулярные выражения находили ‘\n’, где сначала находили конец первой строки и саму ячейку, где есть \n и заменяли их на точку с запятой.
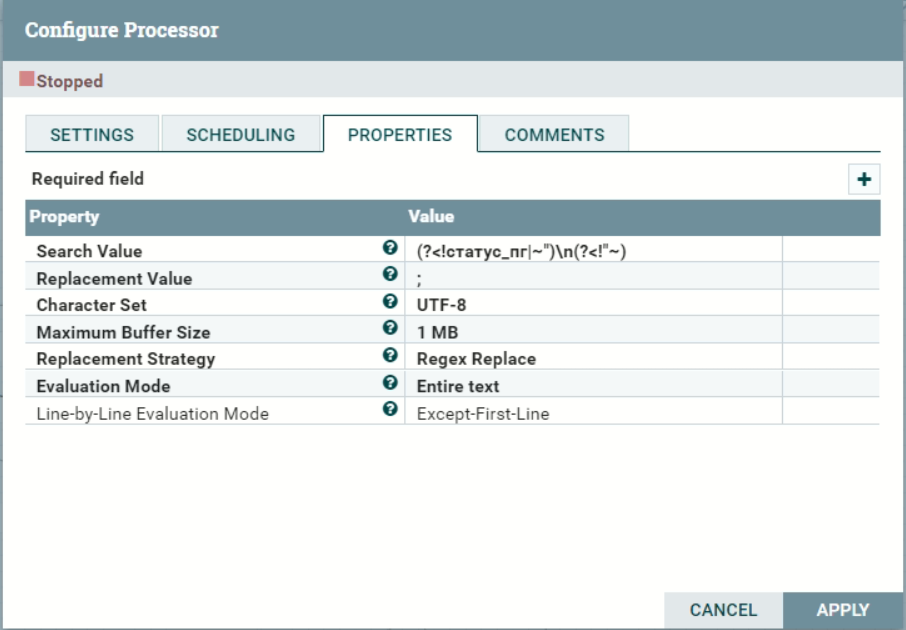
Решили проблему с индексами, но внезапно появилась новая ошибка Cannot create PoolableConnectionFactory, где Put SQL перестал загружать данные в постгрес. Оказалось, что СУБД PostgreSQL упал, а он был развернут также в контейнере. Пришлось заново поднимать новый контейнер (благо все данные были замаунчены через volume) и соединять контейнеры в общую сеть, после чего контейнеры снова стали видеть друг друга.

Наконец, все настроили и в теории все должно было работать гладко, но теория на то и есть теория – редко когда она сразу взлетает. Особенно, если речь про NIFI, где очень много тонкостей и подводных камней.
Так, на практике мы столкнулись с новой ошибкой памяти, а точнее JAVA HEAP SPACE
OutOfMemory error. Да, та самая классическая любимая многими программистами ошибка, когда иногда непонятно, что могло забить всю память.
Решили, что что-то не так с JAVA HEAP - поставили 4 ГБ (к слову, на машине было 16 ГБ, но там жили еще PostgreSQL и Grafana). Но все равно
безрезультатно, падения продолжились.
Начали копать глубже, пытаясь разобраться в особенностях работы процессоров, так как пришло понимание, что проблема в одном из них. Сначала решили проверить Split Text.
Для этого разберемся в особенности работы данного процессора:
Если у вас файл с 20 000 строк и параметр Line Split Count равен 1, Split Text будет делить один файл на 20 000 файлов. Мы поставили еще 2 Split Text процессора, где в первом Line Split Count равен 10 000, во втором Line Split Count равен 2 000. В конце файл с 2 000 строк делился на файлы по 1 строке. Так мы решили проблему с OutOfMemory.

Это решение было временным, и из-за того, что обрабатывалось много данных, так как параллельно работали 5 пайплайнов для загрузки всей истории (15к файлов), они собирались в процессорах и не обрабатывались. В результате появлялась вот такая ошибка: Flow file Repository failed to update, и, по традиции, NIFI снова падал. Эта ошибка оставалась, даже когда 2 пайплайна работало параллельно. Дедлайн по сдаче работ приближался, и было решено для каждого пайплайна поднимать отдельный контейнер.
Но это решение также было временным, так как мы обрабатывали огромное количество данных - 300 000 строк в секунду. Возникла новая ошибка с данными - GC overhead limit exceeded. После анализа проблемы выяснили, что пока процессор обрабатывал один файл приходило еще 10 других. Для решения этой ошибки мы сначала подсчитали, за сколько секунд каждый пайплайн выгружает один файл и на “Total queued data” будет “0/0 bytes”, плюс еще 2-5 секунд в зависимости от объема самого файла. Полученное время мы поставили в интервал Get File.


Результаты
В результате мы успешно выгрузили все 15к файлов, но пайплайны изменились:
1) Get File
2) Convert Excel to Csv
3) Split Text
4) Split Text
5) Split Text
6) Convert Record
7) Update Attribute
8) Replace Text
9) Replace Text
10) Replace Text
11) Update Record
12) Convert Record
13) Convert Json to SQL
14) Put SQL
Выводы
Apache NIFI - это мощный инструмент Big Data для обработки, обогащения, оркестрации и транспорта данных. Инструмент обладает большим количеством встроенных процессоров, которые необходимо умело применять. Они дают возможность инженерам данных настроить практически любую бизнес-логику обработки данных в визуальном интерфейсе проектирования пайплайнов.
Однако нестандартные кейсы по обработке данных, такие, как наличие определенных символов в данных, некорректно заполненные записи на источнике, отсутствие нужных пробелов и прочее, большое количество одновременно загружаемых данных, отсутствие структурированности требуют особых знаний и глубокого понимания работы Apache NIFI. Промышленные решения, как правило, требуют таких углубленных знаний, так как зачастую источники данных являются проблемными, имеют лишние некорректные символы и большие объемы.
Здесь встает резонный вопрос освоения на практике всех подводных камней работы NIFI либо выбора другого инструмента обработки данных. Даже писать на чистом Python покажется многим разработчика более привлекательным и веселым, так как процесс более гибкий и функционально практически неограничен. Также необходимо оперировать сроками проекта, доступной экспертизой в команде, стоимостью разработки, сложностью поддержки решения и рисками проекта. Взвесив все за и против, можно принять решение – идти ли в сторону NIFI. Основной совет может быть – да, идти, если были взвешены все за и против этого подхода.